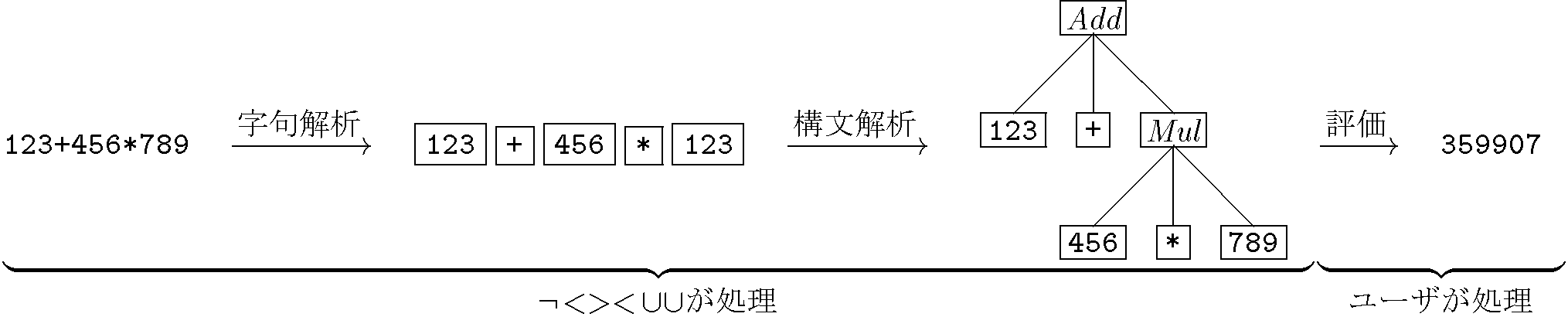
このドキュメントでは、単純な算術式を表す文字列(たとえば "1+1" や "123+456*789")を入力にとり、その値(2 や 359907)を出力するプログラムを作成しながら、¬<><∪∪の基本的な機能の使い方を説明します。このドキュメントは、情報工学の大学学部生程度で、コンパイラなどの言語処理系について学ぼうとしている読者を想定して書かれていますが、形式文法について、算術式の文法がBNFなどを用いてどのように表現され、算術式がどのような解析木(具象構文木)で表現されるかといった程度の知識が必要です(言語処理系などの授業の教科書に載ってますよね?)。また、Java 1.4 のプログラムに関する基本的な知識(文や式を一通りと、再帰呼び出しによる木のトラバース)と、UNIXシェルあるいはコマンドプロンプトといったコンソールについて、javac コマンドで Java のプログラムをコンパイルできる程度の知識が必要です。
このドキュメントでは、算術式の値を計算するプログラムを、字句解析、構文解析、評価の3つの処理で構成します。字句解析では、入力された文字列を、トークン(あるいは字句)と呼ばれる短い文字列に切り分けます。構文解析では、トークンの列を入力に取り、式の構造を表現する木構造(構文木)を出力します。評価では、構文木を入力に取り、式の値を計算するJavaプログラムを作成します。これらのうち、字句解析と構文解析のプログラムは、ユーザが直接記述するのではなく、ユーザが記述した文法に基づいて¬<><∪∪が出力します。評価を行うプログラムは、ユーザが作成します。
このセクションでは、文字列を入力にとり、それをトークンと呼ばれる短い文字列の列に切り分けるプログラムを作成します。このような処理を字句解析と呼び、このような処理を行うプログラムを字句解析器と呼びます。
ここでは、+ などの演算子と括弧は1文字を1つのトークンにし、0~9の数字は、複数文字をまとめて1つのトークンとします。まず、次のテキストを、ExpressionParser.notavacc という名前のファイルに保存します。
// ExpressionParser.notavacc
$parser ExpressionParser;
$token PLUS = "+" ;
$token MINUS = "-" ;
$token STAR = "*" ;
$token SLASH = "/" ;
$token LEFT_PAREN = "(" ;
$token RIGHT_PAREN = ")" ;
$token NUMBER = '0'..'9'+ ;
このコードの意味は後ほど説明することにして、まずこのファイルから構文解析器を作成し、動作を確認してみましょう。コンソール上で、ExpressionParser.notavaccと同じディレクトリに移動し、notavacc --target 1.4 ExpressionParser.notavacc と入力します(¬<><∪∪の bin ディレクトリへパスを通しておく必要があります)。
% notavacc --target 1.4 ExpressionParser.notavacc generating a parser from `ExpressionParser.notavacc'.
字句解析器を含む ExpressionParser.java というファイルが出力されます。出力された字句解析器は単体では実行できないので、次のようなテストプログラムを用意します。
// Test.java
import java.io.*;
public class Test {
public static void main(String[] args) throws Exception {
String text = args[0];
System.out.println("input: " + text);
ExpressionParser.LexicalAnalyzer a
= new ExpressionParser.Default.LexicalAnalyzer("test", text, 8);
for (;;) {
ExpressionParser.Token token = a.next();
if (token.getSymbolID() == ExpressionParser.EOF_TOKEN)
break;
System.out.println(token.getImage());
}
}
}
このプログラムは、第1引数として渡された文字列を、字句解析器によってトークンに分割し、そのトークンを1行ずつに出力します。¬<><∪∪では、構文解析を行う場合、字句解析器を扱うコードをユーザが記述する必要は無いため、このプログラムを細部まで理解する必要はありません。
ExpressionParser.java と Test.java を javac でコンパイルします。
% javac -source 1.4 *.java
以上で、構文解析器とそのテストプログラムが用意できました。いくつか入力を与えて、結果を確かめてみましょう。
% java Test "1+1" input: 1+1 1 + 1
% java Test "123+456*789" input: 123+456*789 123 + 456 * 789
% java Test "8-)" input: 8-) 8 - )
最後の例は、数式としては意味を持ちませんが、数値と記号2つの3つのトークンに分割されます。
(このセクションの残りの内容に興味が無い場合、次のセクションに進んでかまいません。)
ExpressionParser.notavacc の説明に戻ります。
// ExpressionParser.notavacc
$parser ExpressionParser;
$token PLUS = "+" ;
$token MINUS = "-" ;
$token STAR = "*" ;
$token SLASH = "/" ;
$token LEFT_PAREN = "(" ;
$token RIGHT_PAREN = ")" ;
$token NUMBER = '0'..'9'+ ;
1行目はコメント、2行目は出力するクラスの名前です(パッケージ名を加えることもできます)。3行目以降が、字句解析器でどのようなトークンを扱うかを記述しています。$token に続き、トークンの種類を表す識別子(構文解析で使用します)、等号(=)、そしてどのようにトークンを切り出すかを記述します。
等号の右側では、Javaの文字列(たとえば "+" や "-")は、その文字列をトークンとして切り出すことを表します。'0'..'9' は 0~9 のいずれか1文字を表し、+は直前の表現の1回以上繰り返したものを表します。従って、'0'..'9'+は、0~9 のいずれかが1文字以上続いたものを表し、これがトークンとして切り出されます。切り出しは、1つのトークンがなるべく長くなるように行われるため、123のような入力は、1つのトークンになり、1と2と3の3つのトークンにはなりません。等号の右側では、これ以外にも、こちらのtokenExpressionの表現を使用することができます(「マッチする文字列」をなるべく長く切り出します)。
上の例では、空白をトークンとして切り出すことを指示していないため、入力に空白が入るとそこで例外が発生します。
% java Test "1 + 1" input: 1 + 1 1 Exception in thread "main" ExpressionParser$ParseException: An invalid character sequence starting with ' ' (line 1, column 2) at ExpressionParser$Default$LexicalAnalyzer.next(ExpressionParser.java:1108) at Test.main(Test.java:12)
1がまず切り出され、その後空白からトークンを切り出すことができないため、例外が発生します。空白を普通のトークンとして切り出しても良いのですが、空白は構文解析を行う上では不要なものです。このような、構文解析上は不要なトークンは、$white を頭につけることで構文解析ではあたかも存在しないかのように扱われます(ただし、今のTest.java プログラムでは、$white であるようなトークンも出力されます)。ExpressionParser.notavacc の末尾に次の行を追加しましょう。
$white $token SPACE = ' '+ ;
また、少し複雑な例として、Javaの /*~*/ スタイルのコメントを扱えるようにしましょう。次は一見正しいものの、問題がある例です。
$white $token COMMENT = "/*" '\u0000'..'\uFFFF'* "*/";
これは、/* で始まり、文字コードが0~0xFFFFの文字(つまり任意の文字)が0個以上続き、*/ で終わる文字列をトークンとして切り出すことを意味しています。上の行を ExpressionParser.notavacc に加え、notavacc と javac によってコンパイルしてください。
% notavacc --target 1.4 ExpressionParser.notavacc generating a parser from `ExpressionParser.notavacc'. % javac -source 1.4 *.java
このプログラムは、コメントが1つしかないときはうまく動きます(ついでに、スペースをうまく処理していることを確認しましょう)。
% java Test "1/*comment1*/+ 1" input: 1/*comment1*/+ 1 1 /*comment1*/ + 1
しかし、コメントが2つある場合は、次のように、コメントに挟まれた部分を道連れにして、まとめて1つのトークンとして切り出してしまいます。
% java Test "1/*comment1*/+/*comment2*/1" input: 1/*comment1*/+/*comment2*/1 1 /*comment1*/+/*comment2*/ 1
これは、「/* で始まり、任意の文字が0個以上続き、*/ で終わる文字列」をなるべく長く切り出した結果です。もし字句解析器が、なるべく短く切り出すような処理を行えば、正しくコメントをトークンへ切り出すことができます。¬<><∪∪では、なるべく短い文字列を切り出すことを指示する特別な命令はありませんが、マイナス記号を用いることで、コメントを扱うことができます。表現 x が表現するなるべく短い文字列は、x - (x '\u0000'..'\uFFFF'+) で表現することができます。マイナス記号は、その左側が表現する文字列で、その右側で表現する文字列でないものを表します。これを用いることで、コメントは次のように表現できます。
$white $token COMMENT = ("/*" '\u0000'..'\uFFFF'* "*/") - ("/*" '\u0000'..'\uFFFF'* "*/" '\u0000'..'\uFFFF'+);
これは、「/* で始まり */ で終わる任意の文字列で、コメントとみなせる文字列に1文字以上文字が続いたものではないもの」を表します。
ところで、この例では同じ表現が繰り返し出てきます。¬<><∪∪では、このような表現を識別子に割り当てることで、読みやすさを向上させることができます。
$subtoken ANY_CHARACTER = '\u0000'..'\uFFFF' ; $subtoken COMMENT_WIDE_MATCH = "/*" ANY_CHARACTER* "*/" ; $white $token COMMENT = COMMENT_WIDE_MATCH - ( COMMENT_WIDE_MATCH ANY_CHARACTER+ ) ;
$subtoken は、等号の右側の表現を、左側の識別子で表現できるようにします。$subtoken 自体はトークンの切り出しを指示するものではありません。
正しくコメントを扱う ExpressionParser.java は次のようになります。
// ExpressionParser.notavacc
$parser ExpressionParser;
$token PLUS = "+" ;
$token MINUS = "-" ;
$token STAR = "*" ;
$token SLASH = "/" ;
$token LEFT_PAREN = "(" ;
$token RIGHT_PAREN = ")" ;
$token NUMBER = '0'..'9'+ ;
$white $token SPACE = ' '+ ;
$subtoken ANY_CHARACTER = '\u0000'..'\uFFFF' ;
$subtoken COMMENT_WIDE_MATCH = "/*" ANY_CHARACTER* "*/" ;
$white $token COMMENT = COMMENT_WIDE_MATCH - ( COMMENT_WIDE_MATCH ANY_CHARACTER+ ) ;
コンパイルし、動作を確認してみましょう。
% notavacc --target 1.4 ExpressionParser.notavacc generating a parser from `ExpressionParser.notavacc'. % javac -source 1.4 *.java % java Test "1/*comment1*/+/*comment2*/1" input: 1/*comment1*/+/*comment2*/1 1 /*comment1*/ + /*comment2*/ 1
セクションの最後に、いくつか注意すべき点を指摘しておきます。
長さ0の文字列をトークンとして切り出すようなコードは、コンパイルエラーになります(無限にトークンを切り出せてしまうからです)。次は、長さ0以上の数字の列を切り出そうとした例です。
// ExpressionParser.notavacc $parser ExpressionParser; $token NUMBER = '0'..'9'* ;
% notavacc --target 1.4 ExpressionParser.notavacc generating a parser from `ExpressionParser.notavacc'. ExpressionParser.notavacc:4:8: The terminal `NUMBER' (line 4, column 8) should not match the empty string.
「empty string」を切り出そうとしているとして、エラーになります。
種類の異なるトークンが、同じ文字列を切り出そうとしてはいけません(切り出した後で種類がどちらなのか判断できないからです)。次は、IDENTIFIER といくつかのキーワード(PUBLIC など)を定義したものの、キーワードが IDENTIFIER ともみなせるためにエラーになっています。
// ExpressionParser.notavacc $parser ExpressionParser; $token IDENTIFIER = ( IDENTIFIER_START IDENTIFIER_PART* ); $subtoken IDENTIFIER_START = '$' | 'A'..'Z' | '_' | 'a'..'z' | '\u0080'..'\uffff' ; $subtoken IDENTIFIER_PART = '0'..'9' | IDENTIFIER_START ; $token PUBLIC = "public" ; $token CLASS = "class" ; $token INT = "int" ;
% notavacc --target 1.4 ExpressionParser.notavacc generating a parser from `ExpressionParser.notavacc'. ExpressionParser.notavacc:4:8: The following match the same string. ExpressionParser.notavacc:4:8: `IDENTIFIER' (line 4, column 8) ExpressionParser.notavacc:10:8: `INT' (line 10, column 8) ExpressionParser.notavacc:4:8: The following match the same string. ExpressionParser.notavacc:4:8: `IDENTIFIER' (line 4, column 8) ExpressionParser.notavacc:9:8: `CLASS' (line 9, column 8) ExpressionParser.notavacc:4:8: The following match the same string. ExpressionParser.notavacc:4:8: `IDENTIFIER' (line 4, column 8) ExpressionParser.notavacc:8:8: `PUBLIC' (line 8, column 8)
このエラーを避けるには、IDENTIFIER から明示的にキーワードを除きます。
// ExpressionParser.notavacc $parser ExpressionParser; $token IDENTIFIER = ( IDENTIFIER_START IDENTIFIER_PART* ) - KEYWORDS; $subtoken IDENTIFIER_START = '$' | 'A'..'Z' | '_' | 'a'..'z' | '\u0080'..'\uffff' ; $subtoken IDENTIFIER_PART = '0'..'9' | IDENTIFIER_START ; $subtoken KEYWORDS = "public" | "class" | "int" ; $token PUBLIC = "public" ; $token CLASS = "class" ; $token INT = "int" ;
% notavacc --target 1.4 ExpressionParser.notavacc generating a parser from `ExpressionParser.notavacc'.
このセクションでは、字句解析器が出力するトークンの列を入力にとり、式の構造を構文木と呼ばれる木で表現します。このような処理を構文解析と呼び、このような処理を行うプログラムを構文解析器と呼びます。
まず、算術式の文法が、BNFを用いて次のように表現できることを思い出してください。
Expression ::= Expression + Term
| Expression - Term
| Term
Term ::= Term * Factor
| Term / Factor
| Factor
Factor ::= ( Expression )
| Number
これを、単純に¬<><∪∪の記法で記述すると次のようになります(ここでは、前のセクションで途中を飛ばした読者のために、空白やコメントは扱わない物を示しますが、SPACE や COMMENT などの $white $token を追加してもかまいません)。
// ExpressionParser.notavacc
$parser ExpressionParser;
$token PLUS = "+" ;
$token MINUS = "-" ;
$token STAR = "*" ;
$token SLASH = "/" ;
$token LEFT_PAREN = "(" ;
$token RIGHT_PAREN = ")" ;
$token NUMBER = '0'..'9'+ ;
$parsable
Expression { Expression PLUS Term
| Expression MINUS Term
| Term
}
Term { Term STAR Factor
| Term SLASH Factor
| Factor
}
Factor { LEFT_PAREN Expression RIGHT_PAREN
| NUMBER
}
前半は字句解析のための定義、後半は構文解析のための定義になります。後半は、BNFの ::= の右側を { ... } のように囲うようにし、トークンを表す場合は、$token で定義した識別子を使います。また、テキスト全体を表している Expression の前には $parsable を付け、これによって parseExpression という名前の、字句解析と構文解析を一度に行うメソッドが生成されます。
次のテストプログラムとあわせてコンパイルします(このプログラムは、一通り理解してください)。
// Test.java
import java.io.*;
import java.util.*;
public class Test {
public static void main(String[] args) throws Exception {
String text = args[0];
System.out.println("input: " + text);
ExpressionParser p = new ExpressionParser();
ExpressionParser.Node expr = p.parseExpression("test", text, 8);
dump("", expr);
}
public static void dump(String indent, ExpressionParser.Node node) {
if (node instanceof ExpressionParser.Token) {
ExpressionParser.Token token = (ExpressionParser.Token) node;
System.out.println(indent + token.getImage());
} else {
String className = node.getClass().getName();
System.out.println(indent + className);
Iterator it = node.getChildNodes().iterator();
while (it.hasNext()) {
ExpressionParser.Node child = (ExpressionParser.Node) it.next();
dump(indent + " ", child);
}
}
}
}
parseExpression で字句解析と構文解析を行い、得られた構文木を dump によって出力します。parseExpression の引数は、テキストの名前、テキスト、テキスト中のタブ文字が空白何文字に相当するか、の3つです。構文木のノードは ExpressionParser.Node のサブクラスで表されます。dump では、木を再帰的にたどります。トークンであればその文字列を getImage() によって得て出力し、そうでなければクラス名を getClass().getName() によって得て出力して、getChildNodes() で得られる子のリストに対して、再帰的に dump を呼び出します。
% notavacc --target 1.4 ExpressionParser.notavacc generating a parser from `ExpressionParser.notavacc'. % javac -source 1.4 *.java
以上で、構文解析器とそのテストプログラムが用意できました。いくつか入力を与えて、結果を確かめてみましょう。
% java Test "1+1"
input: 1+1
ExpressionParser$Default$Expression
ExpressionParser$Default$Expression
ExpressionParser$Default$Term
ExpressionParser$Default$Factor
1
+
ExpressionParser$Default$Term
ExpressionParser$Default$Factor
1
3行目から下が木を表現している部分になり、ノードの子は、空白2文字分右にずらされて下に表示されます。クラス名の出力が妙な形式になっていますが、各行2つ目の$の右側を見てください。3行目の Expression の子は、4行目の Expression、+、+ の次の行の Term となり、教科書どおりの解析木が得られています。
% java Test "123+456*789"
input: 123+456*789
ExpressionParser$Default$Expression
ExpressionParser$Default$Expression
ExpressionParser$Default$Term
ExpressionParser$Default$Factor
123
+
ExpressionParser$Default$Term
ExpressionParser$Default$Term
ExpressionParser$Default$Factor
456
*
ExpressionParser$Default$Factor
789
% java Test "8-)"
input: 8-)
Exception in thread "main" ExpressionParser$ParseException: The token `)' (line 1, column 3) should be one of the following.
LEFT_PAREN
NUMBER
at ExpressionParser.__error__notavacc_reserved(ExpressionParser.java:1993)
at ExpressionParser.__error__notavacc_reserved(ExpressionParser.java:1941)
at ExpressionParser.__parse__notavacc_reserved(ExpressionParser.java:1676)
at ExpressionParser.parseExpression(ExpressionParser.java:630)
at ExpressionParser.parseExpression(ExpressionParser.java:614)
at Test.main(Test.java:11)
最後の例は、式ではないのでエラーになります。8- までは例えば 8-8 のような式の一部かもしれないのでエラーにはなりません。しかし 8-) で始まるような式は存在しないので、) に到達した時点でエラーとなります。
このような構文木を元に評価を行うプログラムを作成してもいいのですが、評価における処理を簡単にするために若干の修正を行います。経験を積んでいない読者が、世の中に既に存在するBNFを簡単に¬<><∪∪に転用できるように、ここでは次の単純なルールに基づいて変更を行います(拡張BNFを扱いたい場合、教科書などを参考に、事前にBNFへ変換しておいてください)。
まず、元のBNFについて、| を1つ以上含むような Left ::= Right1 | Right2 | ... に対して次の操作を行います。Right? を順に見ていき、それが2つ以上のシンボルからできていれば、Right? を新しいシンボルで置き換えて、新しいシンボル ::= Right? を導入します。例えば、Expression ::= ... を見ると、Expression + Term は3つのシンボルでできているので Addition で置き換えて、Addition ::= Expression + Term を新しく導入します。算術式の BNF は次のように書き換えられます。
Expression ::= Addition
| Subtraction
| Term
Addition ::= Expression + Term
Subtraction ::= Expression - Term
Term ::= Multiplication
| Division
| Factor
Multiplication ::= Term * Factor
Division ::= Term / Factor
Factor ::= Paren
| Number
Paren ::= ( Expression )
変更された BNF をみると、::= の右側は、
| を含まない1つ以上のシンボルの列であるもの(例えば Expression + Term)| を含むが、| で区切られた個々の要素は単独のシンボルであるもの(例えば Addition | Subtraction | Term)のいずれかになります。この BNF を、¬<><∪∪の記法に直します。(1) に対しては、先ほど示したような Left { Right } という記法で表現します。(2) については、Left = Right1 | Right2 | ... ; という記法を用います。さらに、全体を現すシンボル(この場合 Expression)が (2) の形をしている場合、全体を現す新しいシンボル(今回は Root という名前にしましょう)を導入し、それは (1) の形式で記述します((2) の形式には $parsable を付けられないためです)。この結果は次のようになります。
// ExpressionParser.notavacc
$parser ExpressionParser;
$token PLUS = "+" ;
$token MINUS = "-" ;
$token STAR = "*" ;
$token SLASH = "/" ;
$token LEFT_PAREN = "(" ;
$token RIGHT_PAREN = ")" ;
$token NUMBER = '0'..'9'+ ;
$parsable
Root { expression }
expression = Addition
| Subtraction
| term
;
Addition { expression PLUS term }
Subtraction { expression MINUS term }
term = Multiplication
| Division
| factor
;
Multiplication { term STAR factor }
Division { term SLASH factor }
factor = Paren
| NUMBER
;
Paren { LEFT_PAREN expression RIGHT_PAREN }
Left = Right1 | Right2 | ... ; の形式で定義された Left は、全て先頭が小文字で始まっていることに気づきましたか? ($token は全体が大文字で、Left { Right } で定義される Left は全て先頭が大文字だったことにも気づいていましたか?) 実際には、このような Left を全て大文字で記述したり、$token を小文字で記述しても、¬<><∪∪は動作するコードを出力します。しかし、¬<><∪∪に限らずプログラム言語一般について、このような大文字・小文字の使い分けは、メジャーなものを真似するようにした方が良いでしょう。これは、プログラムのソースを人に見せたり見せられたりしたときに、人によって大文字小文字の使い方がバラバラだと、理解の効率が悪くなるためです。同じことが、スペースや改行の入れ方についても言えます。なお、¬<><∪∪がこのような使い分けをしていないプログラムをエラーにしないのは、今作って実行したらもう捨ててしまうようなプログラムについてまでもそのような使い分けを強制するのを避けたいからです。
$parsable が Expression から Root になったため、テストプログラムも1箇所だけ修正が必要です。
// Test.java
import java.io.*;
import java.util.*;
public class Test {
public static void main(String[] args) throws Exception {
String text = args[0];
System.out.println("input: " + text);
ExpressionParser p = new ExpressionParser();
ExpressionParser.Node expr = p.parseRoot("test", text, 8);
dump("", expr);
}
public static void dump(String indent, ExpressionParser.Node node) {
if (node instanceof ExpressionParser.Token) {
ExpressionParser.Token token = (ExpressionParser.Token) node;
System.out.println(indent + token.getImage());
} else {
String className = node.getClass().getName();
System.out.println(indent + className);
Iterator it = node.getChildNodes().iterator();
while (it.hasNext()) {
ExpressionParser.Node child = (ExpressionParser.Node) it.next();
dump(indent + " ", child);
}
}
}
}
再びコンパイルを行い、いくつか入力を与えてみましょう。
% notavacc --target 1.4 ExpressionParser.notavacc generating a parser from `ExpressionParser.notavacc'. % javac -source 1.4 *.java
% java Test "1+1"
input: 1+1
ExpressionParser$Default$Root
ExpressionParser$Default$Addition
1
+
1
% java Test "123+456*789"
input: 123+456*789
ExpressionParser$Default$Root
ExpressionParser$Default$Addition
123
+
ExpressionParser$Default$Multiplication
456
*
789
ノードの数がだいぶ減り、すっきりした構文木が得られました。(1) の形式からだけノードが作られ、(2) の形式からノードが作られていないことがわかります。
セクションの最後に、(2) のケースのために導入した記法がどのような意味を持っていて、なぜ上のような構文木が得られるのかを説明します(ただし、この説明は全く正しいわけでは無いので、より厳密に理解したい場合は他のドキュメントを参照してください)。興味が無い場合、次のセクションに進んでかまいません。
Left = Right1 | Right2 | ... ; は、(字句解析における $subtoken に似て)Left が他の場所で使われたときに、それを Right1 | Right2 | ... に置き換える効果があります。例えば、Root { expression } は、Root { Addition | Subtraction | term } と解釈され、さらにterm を置き換えて Root { Addition | Subtraction | ( Multiplication | Division | factor ) } と解釈されます。factor も置き換えますから、これは、次のように解釈されます。
Root { Addition
| Subtraction
| Multiplication
| Division
| Paren
| NUMBER
}
このような置き換えを行って Left = Right1 | Right2 | ... ; の形式を全て取り除き、Left { Right } の形式だけで文法を構成することで、得られる構文木が上で示したようなすっきりした形のものになります。
構文木を入力に取り、式の値を出力するプログラムを作ります。前のセクションで使用した Test.java を基に考えてみましょう。dump は、node で与えられたノードを出力していましたが、これを node が表現している算術式の値を返すように変更することを考えます。大まかな形は次のようになります(このプログラムはコンパイルできません)。
// Test.java
import java.io.*;
import java.util.*;
public class Test {
public static void main(String[] args) throws Exception {
String text = args[0];
System.out.println("input: " + text);
ExpressionParser p = new ExpressionParser();
ExpressionParser.Node expr = p.parseRoot("test", text, 8);
double value = evaluate(expr);
System.out.println(value);
}
public static double evaluate(ExpressionParser.Node node) {
if (node instanceof ExpressionParser.Token) {
ExpressionParser.Token token = (ExpressionParser.Token) node;
String image = token.getImage();
return Double.parseDouble(image);
} else if (node instanceof ExpressionParser.Addition) {
double v1 = evaluate( <+の左の式> );
double v2 = evaluate( <+の右の式> );
return v1 + v2;
} else if (node instanceof ExpressionParser.Subtraction) {
double v1 = evaluate( <-の左の式> );
double v2 = evaluate( <-の右の式> );
return v1 - v2;
} else if (node instanceof ExpressionParser.Multiplication) {
double v1 = evaluate( <*の左の式> );
double v2 = evaluate( <*の右の式> );
return v1 * v2;
} else if (node instanceof ExpressionParser.Division) {
double v1 = evaluate( </の左の式> );
double v2 = evaluate( </の右の式> );
return v1 / v2;
} else if (node instanceof ExpressionParser.Paren) {
double v = evaluate( <括弧に囲まれた式> );
return v;
} else if (node instanceof ExpressionParser.Root) {
double v = evaluate( <式> );
return v;
} else {
throw new IllegalArgumentException("" + node);
}
}
}
node の種類は、instanceof によって判別することができます。この例では、instanceof によって種類を判別した後、それが Token(NUMBER であることを期待しています)であれば、その値を parseDouble によって得ます。それが Addition (足し算)ならば、+ 記号の左右の式の値を evaluate によって求め、その値を足します。他も同様です。
+ 記号の左右の式を表すノードを求めるのには、dump で使用した getChildNodes を使うこともできますが、その場合1つ目の子供(getChildNodes().get(0))、3つ目の子供(getChildNodes().get(2))といった形で、子供を指定しなければなりません。このような数字は、evaluateを見ただけではその意味が分からず、デバッグ時に原因を特定するのを困難にしたり、ExpressionParser.notavacc を修正したときに修正ミス等が発生させやすくしたりするため、好ましくありません(このような数字は一般にマジックナンバーと呼ばれます)。
¬<><∪∪では、文法においてノードにラベルを付けることで、Javaのプログラムからそのラベル名を用いて子にアクセスすることができます。ExpressionParser.notavacc を次のように修正します。
// ExpressionParser.notavacc
$parser ExpressionParser;
$token PLUS = "+" ;
$token MINUS = "-" ;
$token STAR = "*" ;
$token SLASH = "/" ;
$token LEFT_PAREN = "(" ;
$token RIGHT_PAREN = ")" ;
$token NUMBER = '0'..'9'+ ;
$parsable
Root { expression:expression }
expression = Addition
| Subtraction
| term
;
Addition { operand1:expression PLUS operand2:term }
Subtraction { operand1:expression MINUS operand2:term }
term = Multiplication
| Division
| factor
;
Multiplication { operand1:term STAR operand2:factor }
Division { operand1:term SLASH operand2:factor }
factor = Paren
| NUMBER
;
Paren { LEFT_PAREN expression:expression RIGHT_PAREN }
新たに導入された、コロン(:)の左側のoperand1などがラベルで、右側のシンボルをラベル付けしています。評価のプログラムは次のようになります。
// Test.java
import java.io.*;
import java.util.*;
public class Test {
public static void main(String[] args) throws Exception {
String text = args[0];
System.out.println("input: " + text);
ExpressionParser p = new ExpressionParser();
ExpressionParser.Node expr = p.parseRoot("test", text, 8);
double value = evaluate(expr);
System.out.println(value);
}
public static double evaluate(ExpressionParser.Node node) {
if (node instanceof ExpressionParser.Token) {
ExpressionParser.Token token = (ExpressionParser.Token) node;
String image = token.getImage();
return Double.parseDouble(image);
} else if (node instanceof ExpressionParser.Addition) {
ExpressionParser.Addition n = (ExpressionParser.Addition) node;
double v1 = evaluate(n.operand1());
double v2 = evaluate(n.operand2());
return v1 + v2;
} else if (node instanceof ExpressionParser.Subtraction) {
ExpressionParser.Subtraction n = (ExpressionParser.Subtraction) node;
double v1 = evaluate(n.operand1());
double v2 = evaluate(n.operand2());
return v1 - v2;
} else if (node instanceof ExpressionParser.Multiplication) {
ExpressionParser.Multiplication n = (ExpressionParser.Multiplication) node;
double v1 = evaluate(n.operand1());
double v2 = evaluate(n.operand2());
return v1 * v2;
} else if (node instanceof ExpressionParser.Division) {
ExpressionParser.Division n = (ExpressionParser.Division) node;
double v1 = evaluate(n.operand1());
double v2 = evaluate(n.operand2());
return v1 / v2;
} else if (node instanceof ExpressionParser.Paren) {
ExpressionParser.Paren n = (ExpressionParser.Paren) node;
double v = evaluate(n.expression());
return v;
} else if (node instanceof ExpressionParser.Root) {
ExpressionParser.Root n = (ExpressionParser.Root) node;
double v = evaluate(n.expression());
return v;
} else {
throw new IllegalArgumentException("" + node);
}
}
}
Java のプログラムでは、ExpressionParser.Addition などにキャストした後で、operand1 などのラベルと同名のメソッドを用いることで、ラベル付けされた子ノードを得ることができます。
コンパイルを行い、いくつか入力を与えてみましょう。
% notavacc --target 1.4 ExpressionParser.notavacc generating a parser from `ExpressionParser.notavacc'. % javac -source 1.4 *.java
% java Test "1+1" input: 1+1 2.0
% java Test "123+456*789" input: 123+456*789 359907.0
% java Test "12+(34-56*78)/90" input: 12+(34-56*78)/90 -36.15555555555556
確かに、正しく動いています。
以上で動くプログラムができましたが、最後に、文法ファイルを省略記法を用いて少しだけ簡単にし、また、テキストファイルを構文解析するように修正しましょう。興味が無ければ、この先は読まなくてもかまいません。
これまでの例では、$token において、"+" などの単一の文字列で定義されるトークンにも PLUS などの識別子を割り当て、構文解析を扱う文法中では識別子によってこれらのトークンを参照していました(expression PLUS term のように)。¬<><∪∪では、このような単一の文字列で指定されるトークンに限り、$token の宣言を行わずに文字列自体を文法に埋め込むことができます。
また、Additon { ... } で定義される Addition は、expression = ... の1箇所でしか使われていませんでしたが、使用が1箇所しかないのならば、定義と使用を一度に行うことができます。これにより、Addition を2度もタイプせずに済ますことができ、なにより、文法を読むときに定義箇所や使用箇所を一々探す手間が省け見通しがよくなります。
このような変更を加えた文法ファイルは、次のようになります。今回は、字句解析 で扱ったスペースやコメントも入れ、タブ('\t)と改行('\n'と'\r)も扱うようにしました。
// ExpressionParser.notavacc
$parser ExpressionParser;
$token NUMBER = '0'..'9'+ ;
$white $token SPACE = ( ' ' | '\t' | '\n' | '\r' )+ ;
$subtoken ANY_CHARACTER = '\u0000'..'\uFFFF' ;
$subtoken COMMENT_WIDE_MATCH = "/*" ANY_CHARACTER* "*/" ;
$white $token COMMENT = COMMENT_WIDE_MATCH - ( COMMENT_WIDE_MATCH ANY_CHARACTER+ ) ;
$parsable
Root { expression:expression }
expression = Addition { operand1:expression "+" operand2:term }
| Subtraction { operand1:expression "-" operand2:term }
| term
;
term = Multiplication { operand1:term "*" operand2:factor }
| Division { operand1:term "/" operand2:factor }
| factor
;
factor = Paren { "(" expression:expression ")" }
| NUMBER
;
ファイルを構文解析するには、parseRoot の引数を、ファイルとファイルのエンコーディング名(null はデフォルトのエンコーディングを意味します)に変更するだけです(タブは8文字単位になります)。
// Test.java
import java.io.*;
import java.util.*;
public class Test {
public static void main(String[] args) throws Exception {
ExpressionParser p = new ExpressionParser();
ExpressionParser.Node expr = p.parseRoot(new File(args[0]), null);
double value = evaluate(expr);
System.out.println(value);
}
public static double evaluate(ExpressionParser.Node node) {
if (node instanceof ExpressionParser.Token) {
ExpressionParser.Token token = (ExpressionParser.Token) node;
String image = token.getImage();
return Double.parseDouble(image);
} else if (node instanceof ExpressionParser.Addition) {
ExpressionParser.Addition n = (ExpressionParser.Addition) node;
double v1 = evaluate(n.operand1());
double v2 = evaluate(n.operand2());
return v1 + v2;
} else if (node instanceof ExpressionParser.Subtraction) {
ExpressionParser.Subtraction n = (ExpressionParser.Subtraction) node;
double v1 = evaluate(n.operand1());
double v2 = evaluate(n.operand2());
return v1 - v2;
} else if (node instanceof ExpressionParser.Multiplication) {
ExpressionParser.Multiplication n = (ExpressionParser.Multiplication) node;
double v1 = evaluate(n.operand1());
double v2 = evaluate(n.operand2());
return v1 * v2;
} else if (node instanceof ExpressionParser.Division) {
ExpressionParser.Division n = (ExpressionParser.Division) node;
double v1 = evaluate(n.operand1());
double v2 = evaluate(n.operand2());
return v1 / v2;
} else if (node instanceof ExpressionParser.Paren) {
ExpressionParser.Paren n = (ExpressionParser.Paren) node;
double v = evaluate(n.expression());
return v;
} else if (node instanceof ExpressionParser.Root) {
ExpressionParser.Root n = (ExpressionParser.Root) node;
double v = evaluate(n.expression());
return v;
} else {
throw new IllegalArgumentException("" + node);
}
}
}
% notavacc --target 1.4 ExpressionParser.notavacc generating a parser from `ExpressionParser.notavacc'. % javac -source 1.4 *.java
あとは、テキストファイルに数式を入力し、そのファイル名を引数に渡して Test を起動するだけです。
% java Test ファイル名
これでこのドキュメントは終わりです。このドキュメントでは、なるべく内容を絞り、これだけ知っていれば¬<><∪∪を使って何かプログラムを作れるという機能について説明しました。ただし、必ずしも知らなくてもプログラムは組めるという情報であっても、今後のステップアップに重要なものについては多少脱線しても説明を行いました(例えば、BNFの加工は行わずに最後に示した文法を機械的に得ることもできましたが、構文解析 の最後のような原理的な仕組みの説明へつながっていかないため避けました)。